SPRITE Case Study #5: Sunset for Souper Man.
With apologies to Ronnie James Dio.

This is the last case study on SPRITE. We made it. Eventually.
I will note first that after the conclusion of this one, I am fully committed to getting a full version of the method (and some of the existing text) into publication. This is long overdue, and has a goodish tinge of irony — me, an open-science advocate and general loudmouth, is writing about the technical details of something I haven’t released. I’ll be remedying that as soon as possible.
In addition, I can only say (a) I released the details of how SPRITE worked with the very first post — it’s really, really simple — and any competent programmer could jiffy something equivalent up in a language of their choosing in a half-hour (NOTE: I am not a competent programmer, on a good day I’ll give me a ‘grimly adequate’), (b) I’m reliably assured (a) has already happened, just no-one has told me where the damn thing is yet, (c) this isn’t my job, and I work a lot. It’s been a trying time for a number of reasons.
This is also probably my last entry into the ledger of problems with Brian Wansink’s research, because any further criticism doesn’t have much utility. Concerns with this body of work are now undeniable, because of the scope of what’s occurred:
- this is the FORTY-SIXTH paper to come under scrutiny from me and mine… it might even be more;
- so far, his career count for problematic papers is five retracted, thirteen corrected, which is a truly stunning number;
- one of these was seriously unusual in the fact that it was retracted twice, removed once in favour of a correction, then the corrected version was also judged to be insufficiently correctable for publication… this is unprecedented in my experience;
- the issues involved have been covered in the Chronicle of Higher Education, Slate, Forbes, the Boston Globe, Ars Technica, Boing Boing, The Guardian… and probably elsewhere.
- most importantly, all of the above was covered in a long series of articles on Buzzfeed, which included not only full coverage of the issues but some excellent investigative journalism as well, and a similarly long series on Retraction Watch.
So I’ll hazard a guess that more than one of you is a bit sick of it. As a broader issue, this is all now entirely without novelty. “Him again?” says everyone.
Thus, I wouldn’t bring it to your attention again unless it was really worth it.
So, for one last time (for me at least), we must Hoist the Black and sail.
We’re going to do The Big One.

This is Wansink’s eighth-most cited work, with 567 citations. As anyone’s most-cited academic works are generally review papers or books, it is relevant that it is fifth-most cited amongst experimental studies.
It is also easily the best known, and most publicised.
It won the Ig Nobel Prize in 2007 (a Bacchanalian parody of the Nobel, handed out yearly to research which is weird and improbable but still useful… I would be so very happy to win one myself). It has been centrally featured in his book Mindless Eating, the subject of god-knows how many platform presentations, and a towering mountain of coverage all over the planet.
This study is central to establishing the whole lab’s ethos — quirky but ostensibly reliable observations about human eating behaviour. The apparatus from the experiment is even preserved for posterity in the Food and Brand Lab at Cornell:
There’s a glass trophy case filled with items Wansink has made famous, like the bottomless soup bowl that he used to prove that people will eat 73-percent more if their bowl is constantly replenished via a hidden tube. A cool study, if there ever was one.
Cool, indeed.
And considering where we are, and what I do, it might not surprise you to learn it also contains errors which appear fatal to its conclusions.
Forcing SPRITE
Consider a question answered on a Likert-type scale, with answers from 1 to 9, which is given to n=20 people.
Mean=5.20. SD=1.96.
Can this sample exist? Absolutely. SPRITE can find as many solutions as you like which fit the sample parameters well.

If we were ever interested in reconstructing this histogram, we’d need more information to have even the vaguest idea of what we were looking for. We might be able to make some assumptions about central tendency or normality, but often even this isn’t available to us. Questionnaire data is weird — binned, squished into funny truncated shapes, occasionally bimodal, etc.
So, let’s say we include other information. Say these numbers were from a study on how to create polarising political opinions, and “5” on a scale from 1 to 9 meant ‘neither agree nor disagree’, and the 20 people in the study were starting from having a baseline of having no opinion, then were bombarded with information to try to change their minds.
Such a study might report something like: “After the conclusion of the experiment, only n=6 people still reported having no opinion.”
Statements like this are common in survey data of all types — sometimes there’s a category of response meaningful enough that extra information about it is reported separately. Perhaps people who scored lowest on a depression inventory (i.e. had no symptoms vs. some symptoms), or people who passed vs. failed a test, or people who got 100% on an easy test vs. those who made any mistakes at all, and so on.
These are a blessing for SPRITE, because we can do the following:
- make up a basic histogram including 14 values we can shuffle to change the SD, and 6 values we cannot (which, in this case, would all be 5).
- shuffle just the remaining places until we get the right SD for the whole sample
- chuck the solution out if it has the wrong amount of 5’s (yes, there’s a better way to do it, but it doesn’t matter now)
- repeat the above until we have a set of viable histograms
Let’s try it: answers from 1 to 9, given to n=20 people. Mean=5.20. SD=1.96. And including exactly 6 people who answered “5”.

Simple!
We are still finding unique solutions, but they’re starting to more closely resemble something with a central tendency. With more information, or assumptions about the distribution they were drawn from, we could perhaps refine them further still.
Now.
Wansink et al. (2005)
This study investigated whether visual food cues interfered with the physical experience of being full. Every experimental session ran 4 people, 2 with normal bowls of soup (18oz), and 2 with special doctored ones, which were sneakily connected by a tube beneath the table to a whole separate POT of soup, and were set to refill slowly — so, you could eat and eat and eat and the level of the soup bowl would only go down SLOWWWWWWLY.

I like soup. Sounds ideal to me.
(Not mad about the lack of garlic bread, but you can’t have everything, can you.)
Anyway. What the above means is that this self-refilling bowl can decouple the experience of (eating food and being full) from (how the food looks).
Now, if you were aware you were eating more food, it wouldn’t be much of an experiment — you’d have demonstrated that when you trick people into eating more food, they, uh, do. And they know it. Big deal, eh?
So what’s salient here is that the people in the ‘bottomless’ condition ate a great deal more food, but their estimation of their consumption was also off. This interaction is the cornerstone of the ‘mindless eating’ ethos— our little soup warriors reported eating the amount of food it LOOKED like they ate, not the amount they ACTUALLY ate.
Or did they?
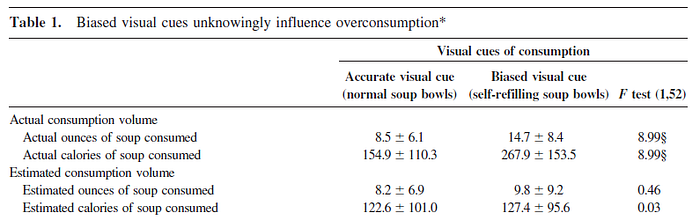
Let’s start with the trick bowls (second row, second column). People estimated they ate 9.8 oz of soup (mean), with an SD of 9.2.
Now there are n=31 people in this condition, and presumably they all eat something — I mean, they came to eat lunch in an experiment which asked them to eat lunch…
Also, the paper mentions that they piloted this experiment, and says:
When given 18-ounce bowls, 61% consumed all of it, and 28% consumed within 1 ounce of one-half of it (8 to 10 ounces).
That is, a full 89% of people in the pilot study are eating 8oz or more.
But just in case someone hates soup and didn’t read the forms when they signed up, and you should NEVER assume undergraduates have read the forms because some of them can’t read, we’ll charitably assume 0 ounces represents a lower bound on consumption.
Seeing as there were ‘six quarts’ of soup attached to the already-full bowl, we can assume the upper bound would be 210 ounces of soup (6 quart pot *32 + 18oz bowl). This is ludicrous, of course. The spoon would be a blur.
So: mean=9.8 oz; SD=9.2 oz, n=31, lower bound=0, upper bound=210.
Does this SPRITE? Yes it does. Here’s a test histogram. Y-axis is count of people, x-axis number of ounces estimated.

This is just one option, of course, but they’re all similar. It’s a bit weird (perhaps we could expect a bit more central tendency?) but not too bad. Lots of people who were just snacking, and then a spray of people who thought they ate more. We could probably force it to have less zero values, but we’d be speculating.
However, a solution like the above is contradicted by the text:

And this is a crucial problem.
This quite clearly says 11 individuals in total estimated they had consumed more than 16 ounces of soup, n=9 in the regular bowls condition, but only n=2 with the self-refilling bowls. Our randomly chosen SPRITE above has n=10.
To test this, we have to run a forcing SPRITE where those n=2 people eating more than 16 ounces are jumbled around a bit, and thrown in with their brethren.
n=2, ≥ 16
n=29, < 16.
And if we do that, we find the only possible distributions are truly odd. To investigate a range of values, I have made our two intrepid soup-estimators report that they received 18oz, 24oz, 30oz, 36oz, or 42oz.
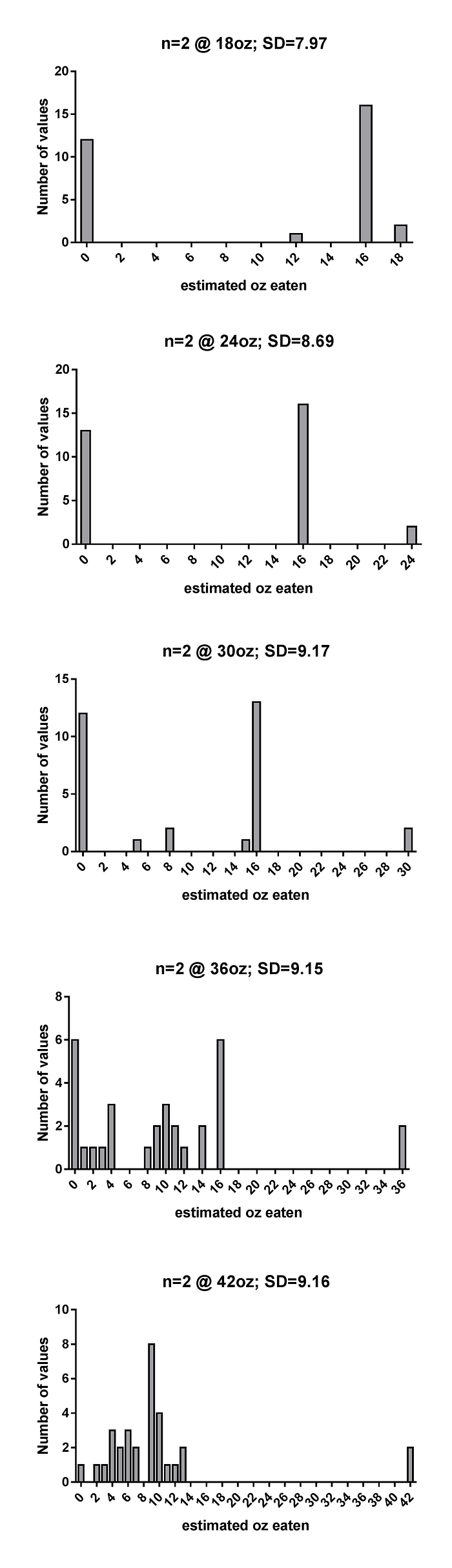
If you look at the SDs at the top of those panels, what this reveals is seriously concerning.
If the intrepid two estimate they ate 18oz or 24oz of soup each, a solution does not even exist. Only the most ludicrous solutions exist at 30oz and 36oz, which require an awful lot of people to guess they ate ZERO ounces of soup (and this is something you can’t estimate incorrectly… you just ate some!) or 15.99 ounces (hey, it’s under 16!)
Both our Souper Troopers need to estimate they ate about 40 ounces each for the rest of the data to look non-ludicrous (and you might have noticed that this would mean it doesn’t look anything like the pilot data… but we’ll get to that).
I can think of three options:
- these people either don’t know what ounces are (they might be international students, after all),
- or they didn’t answer the question seriously (undergraduates!),
- … or the data is incorrectly described.
Whatever the case, if you use the Matoulsky and Brown (2006) method of identifying outliers on the “42” data above, even the most insanely stringent definition of an outlier (Q=0.1%) flags these points as bad. This isn’t surprising, as they have z-scores of 3.52. Grubbs’ Test will flag them, too.
However, if we remove them, the resulting data has a mean of 7.6 and an SD of 3.3… in other words, after eating lots of magic soup, this group of people report eating LESS than the control group, but not significantly (p=0.66). They also now have wildly different variances.
The upshot of all of this is that this mean/SD pair have a great deal of difficulty existing as described.
And we’re not done here. Not by a long shot.
In the control group, people estimated they ate 8.2oz of soup (mean), with an SD of 6.9. And a full n=9 of them estimated they ate 16oz or more of soup.
The most favourable condition for this to exist would be every single one of those people guessing they ate 16 oz. Exactly.
Brace yourself.
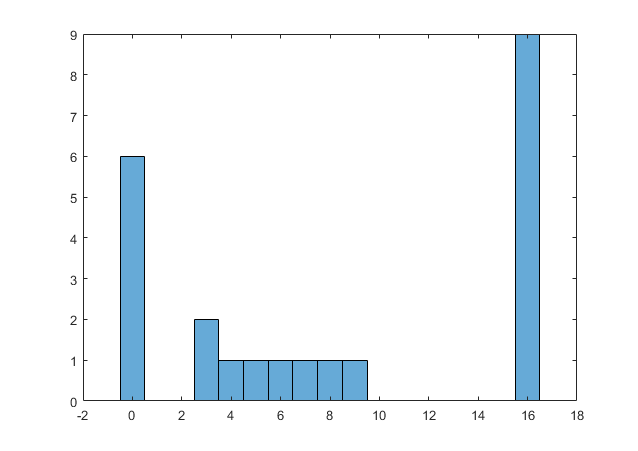
EWW. All the distributions look like this. Weird as the day is long.
And I reiterate: This is the MOST realistic option for n=23, mean=8.2, SD=6.9, with 9 values of 16 or above. It requires an awful lot of people to behave quite, quite strangely.
If we make some of the estimates slightly higher, say, change 3 of those 16’s to 17’s, we are stretching the limit of the data to exist at all…
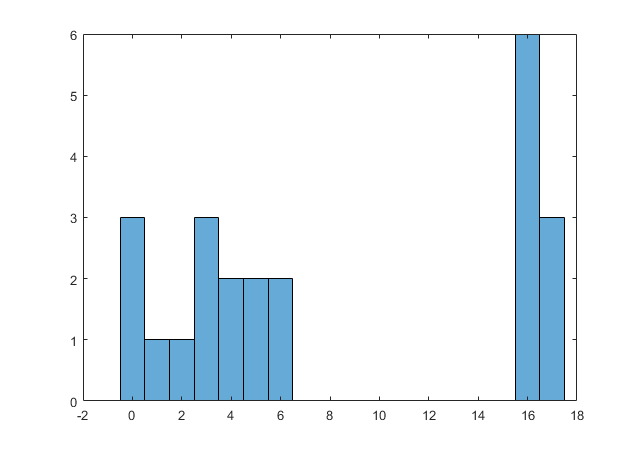
If we change 3 more of the 16’s to 17’s, it is almost at breaking point…
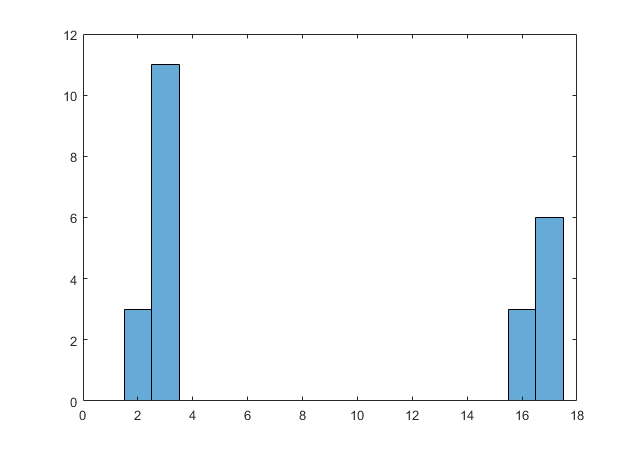
And with any reasonable combination of values higher than this, it snaps, and SPRITE returns no solution (which means there isn’t one). Any values much above 17 will quickly render the whole thing impossible.
Suffice to say, these possible distributions all look about as likely as winning the lottery while getting struck by lightning.
One more thing.
The ‘calories eaten’ numbers provided are just the transform of the soup volume in ounces * 18.22 cals, which is perfectly reasonable caloric density for soup in being halfway between miserable low-cal rehydrated hate-soup (about 10cals/oz), and cream of tomato soup the way I’d make it (more like 30cals/oz). It’s much like Campbell’s condensed tomato, which is 22.5 cals/oz. So we can leave this and concentrate just on the volume eaten.
These are, from the above, Control: mean=8.5, SD=6.1; Bottomless: mean=14.7, SD=8.4.
Now, again we have the problem that comparing the text and the table are a bit confusing. Remember, the salient figure from the reported pilot study was that 89% of participants ate 8 oz or more.
This works just fine for the bottomless condition. Here is a SPRITE that is only a little weird, with 84% above 8 oz.
(Note: the most generous assumption is that a few people weren’t hungry, and everyone else was. That’s why we use 0.)
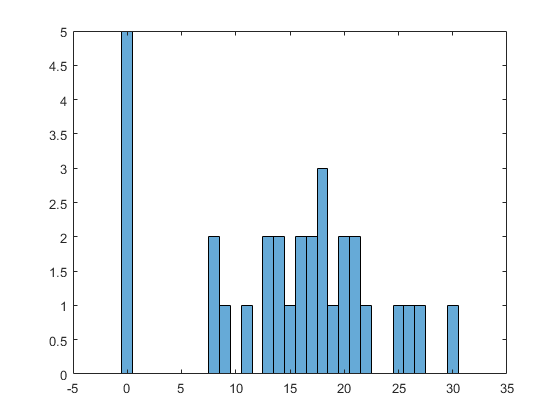
But the control figure, being a lot lower, is a bit of a disaster.

In this, we stuff the closest approximate value (83%) of the n=23 people into categories equal to or above 8 oz.
You don’t even need SPRITE for this one, really. It stands to reason that if you need mean=8.5 & SD=6.1, it is not in any way reasonable to expect the bulk of your values above or equal to 8. Or, if you remember from before, 61% of people eating 18 oz. This is more like, well, 9% (it’s just two people).
The SPRITE is pretty speculative, and you can juke around with this a bit to make it a bit more forgiving, but nothing much changes.
This is certainly less problematic than the problems previously mentioned — pilots are far from 100% reliable, and there isn’t any more data on how the pilot was conducted or how many people were in it. But it certainly isn’t good. We expect pilot studies to at least somewhat describe their later counterparts.
There are other non-SPRITE factors at work here.
- We have not even attempted the unbearably messy task of trying to reproduce the correlations between the actual and estimated consumption. However, compare the estimated bottomless (2 crazy people who thought they ate a whole Warhol catalogue of soup with 29 reasonable values) with the actual bottomless (if anything like the pilot, a few low values and a lot of normally hungry people). Sewing these together seems like it would dictate a surprising amount of people being really, really terrible at soup estimation.
- The paper carefully describes how the diners were laid out in groups of 4, with 2 normal bowls and 2 refillable bowls at each sitting. This is how the table is built! Consequent to that, it is not explained how the cell sizes are n=23 and n=31. These are wildly dissimilar, and neither is divisible by 2. And the overall sample size is n=54 i.e. not divisible by 4. Even if exclusions have been made, the sample sizes contradict the methods as described. Of all the points here, this is also the only one a reviewer could realistically have spotted.
- The 10 p-values on the bottom of Table 1 make me suspicious, because they are all quite non-significant. These aren’t reported but are easily calculated — p=0.5404, 1, 0.5371, 0.6647, 0.8884, 0.8907, 0.4678, 0.3667, 0.2383, 0.8371. However, there is nothing I can reliably glean from these using Carlisle’s method. Two reasons: (1) the problem of non-independence arises here, for instance, the question “I carefully paid attention to how much I ate” is very closely related to “I carefully monitored how much soup I ate”, i.e. these p-values should be closely related to each other; (2) using Stouffer’s Method to combine p-values goes very queer with p-values of 1, as we have here. If this is the case, then the method returns p=0 (which is uninterpretable). Entering the 1 as some version of 0.99999… gives wildly changing p-values depending on the precision. This is not a criticism of the paper in question, just a note of interest. The appropriateness of different omnibus p-values is discussed in a great pre-print here.
Conclusion
The conclusion is this — in my opinion, this paper should be retracted. A lot of soup-related history should be re-written.
This isn’t just a matter of suspicion being congruent to the massive amount of corrections and retractions the author has already garnered. The numbers central to the conclusions of the paper do not describe distributions which can exist in a rational universe. Just below the surface of this rather shiny result is a world of contradiction.
How this came to pass is not my domain. I have no crystal ball and no time machine. Speculating is futile.
And, if we are discussing accuracy, it doesn’t matter. Borked is borked.
Anyway, I hope you’ve had fun — or as close to fun as something like this can be — in our trip through SPRITE. Simple though it may be, you can do a lot with simple tools.

